
12th June, 2026
You can now connect Claude to your Shopify store, your Meta Ads account and your Google Analytics property in about the time it takes to make a coffee. The connectors exist, they are official, and they work. You ask "what was revenue last month and what drove it", and a few seconds later you have three numbers and a confident paragraph explaining them. It feels like the future has arrived.
For a lot of questions, it nearly has. But the gap between an answer that sounds right and an answer you would build a budget around is wider than it looks, and most of that gap is not about whether the numbers are correct. It is about whether the thing answering you knows anything about your business. What you have, fresh out of the box, is a very capable new hire on their first morning: full system access, no idea what was decided in last week's meeting, which tests you have already run and killed, or who you are actually trying to sell to. Fast, articulate, and confident in ways you cannot always check.
The brands that get real leverage out of AI are not the ones with the most connectors. They are the ones that have done the unglamorous work of curating their business into a single layer the AI can read: not just the numbers, but the context around them. This piece is about that layer, why it has two halves rather than one, and what becomes possible when an AI sits on top of the whole thing. It is the layer we build for DTC brands, and it is the part of the picture that separates genuine AI insight from slop.
The layer everything reads from
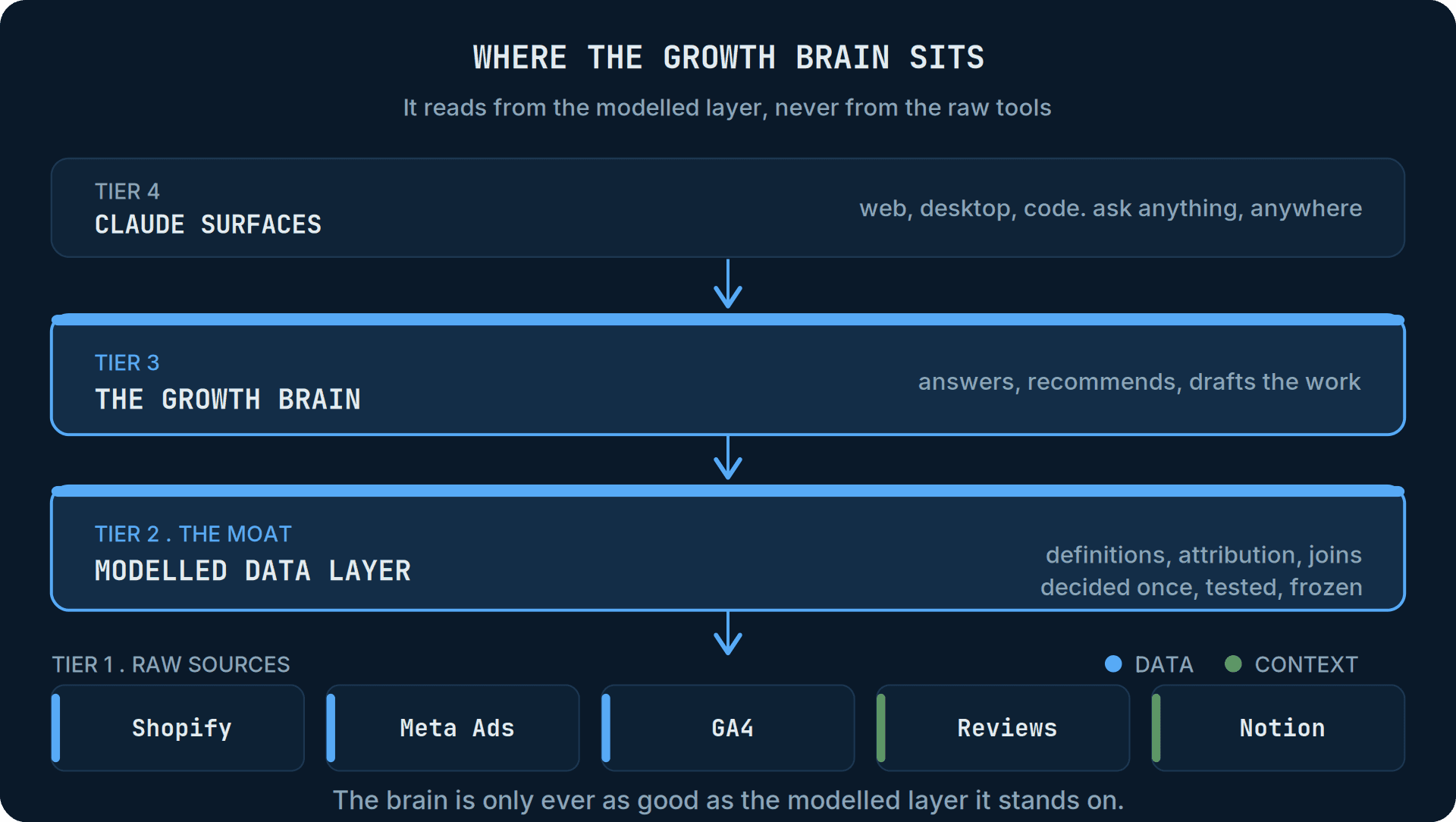
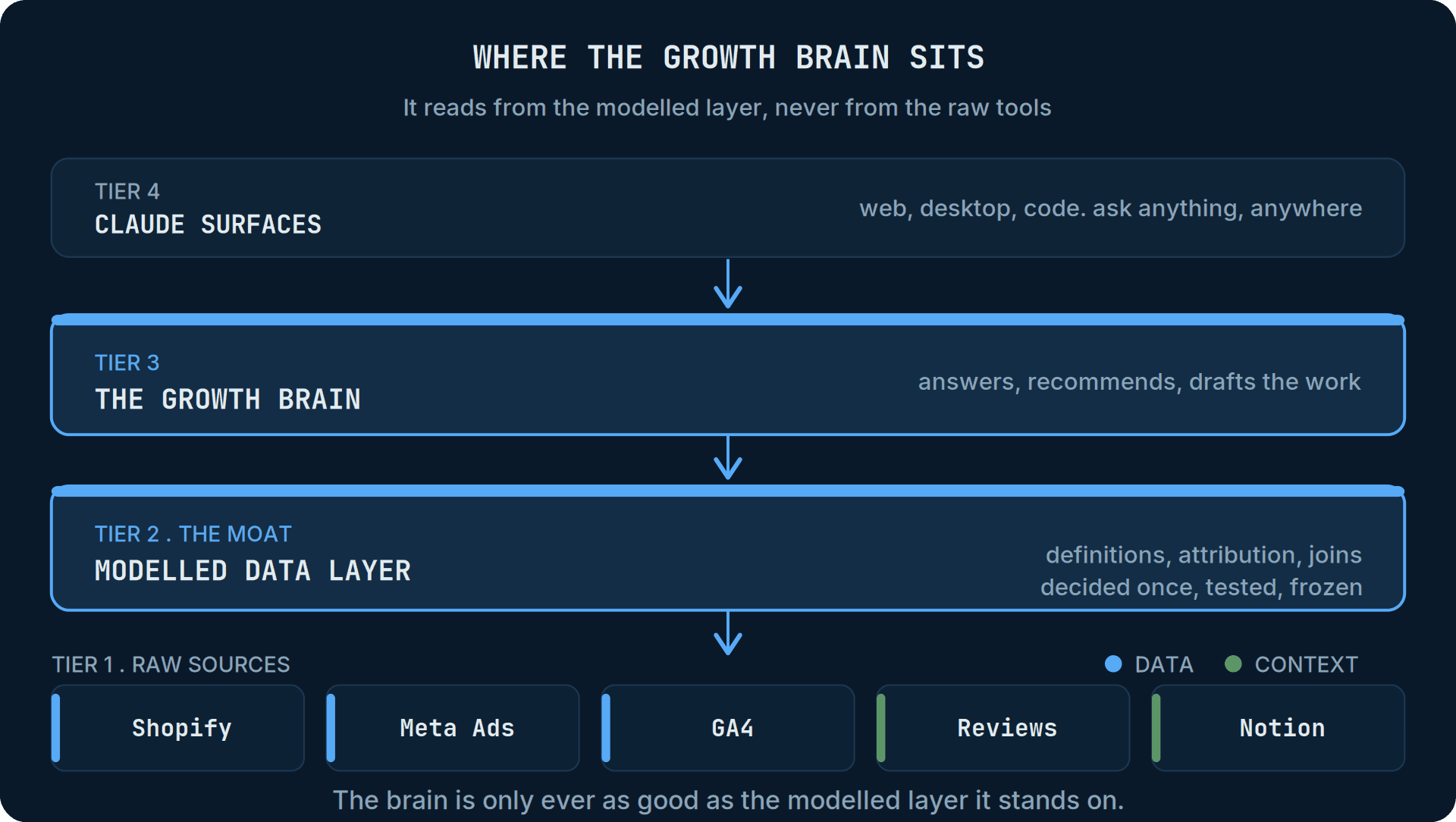
Most of the conversation about AI in ecommerce is about the model. The model is not the constraint. The constraint is what the model is allowed to stand on.
A curated data layer holds two kinds of truth in one place, and the AI reads from that single source rather than scrambling around your raw tools. The first kind is your numbers, reconciled once so that they agree everywhere they appear. The second is your context: the meeting notes, the test backlog, the customer reviews, the strategy for the year, the definition of who you sell to. Numbers tell the AI what happened. Context tells it why that matters to you, and what you would actually do about it.
Wire an AI straight into your tools and you get neither properly. You get raw data feeds it has to reconcile live, and no memory of anything that was ever decided. Put a curated layer in between and the hard work happens once, in a place every answer can stand on. The model stops behaving like a clever stranger and starts behaving like someone who works there.
Pillar one: one set of numbers everyone can trust
Ask three connected tools for revenue last month and you will get three different numbers. Shopify counts orders, Meta counts pixel-attributed purchases on its own attribution window, GA4 counts conversions on a different model again. None of them are lying. They are answering slightly different questions, and the AI dutifully reports whichever one it reached for, with no way of knowing the other two exist.
The deeper problem is that the questions worth asking are almost never single-source. CAC by channel needs ad spend from Meta and Google joined to the actual new customers recorded in Shopify. Repurchase rate by acquisition source needs order history joined to where each customer first came from. Contribution margin by SKU needs product cost joined to returns joined to discounts. A point connector cannot join across sources, so the AI is left to stitch the feeds together inside the conversation, on the fly, slightly differently every time. That reconciliation is slow, it burns tokens reasoning over messy raw payloads, and it is not repeatable. Two people ask the same question and get two answers, and neither can see why. The easy path does not fail loudly. It fails quietly, by being confidently inconsistent, which is the most dangerous failure mode there is, because it looks like it is working.
The fix is a modelled layer between the raw sources and the AI. A warehouse fed by your tools, with a transformation layer that does the reconciling once. It defines what a new customer is, picks one attribution model and applies it consistently, joins spend to customers and orders to costs, and freezes those definitions into clean, tested tables. The AI never touches the raw APIs. It queries the modelled tables, where the hard decisions have already been made, and it inherits correctness rather than re-deriving it, badly, on every question.
This is also the part that compounds. Anyone can connect the Shopify connector in five minutes, and that part is getting more commoditised by the month. The modelled layer is the opposite, the slow asset where every metric you define and every join you get right makes every future answer more trustworthy. The research backs this up. MotherDuck's DABstep work found that with a clean schema, documented columns and pre-computed views, AI agents reached around 93% accuracy on hard analytical questions, outperforming far more elaborate setups. Intelligence was never the bottleneck. The foundational infrastructure was.

Pillar two: the context only your business has
A consistent number tells you that returning revenue fell 12% last month. It does not tell you that you paused a winback flow three weeks ago, that a packaging change shipped in the same window, or that reviews have started mentioning a delivery problem. Those facts are what decide what the number means, and they live nowhere near your warehouse. They sit in your meeting notes, your test backlog, your reviews and your strategy docs, and almost no AI setup can see any of it.
The second half of the layer fixes that. The same curated layer that holds your numbers can ingest your unstructured context and make it retrievable. It can pull in your meeting notes, so the AI knows what was decided and why. It can hold your experiment backlog from Notion, every hypothesis you have tested, what won, what lost and what you learned. It can take your customer reviews and survey verbatims, in the customer's own words. It can read your strategy for the year and the targets behind it, and your ICP definitions, so the AI knows who you are actually trying to reach. It can even ingest ad comments, where creative fatigue and the real objections tend to surface first.
Underneath, this is retrieval. Each document is broken into chunks and stored by meaning, so the AI pulls the handful most relevant to whatever you have just asked, rather than matching keywords. Ask "what did we decide about Meta strategy" and it surfaces the meeting note where you paused lower-funnel campaigns, even though the note never uses the word "strategy". The AI is no longer reasoning from generic best practice it absorbed from the public internet. It is reasoning from your operating history.
That is the difference between an AI that gives you a textbook answer and one that gives you your answer. Ask a generic tool why repeat rate is soft and it will list the usual suspects: weak email, no winback, not enough reasons to come back. All true, none specific. Ask one sitting on your context and it will tell you that the winback flow you paused on the 3rd is the most likely cause, that you ran a similar discount last spring and it lifted repeat rate by four points, and that two recent reviews flagged the same friction at checkout. Same question. One answer is plausible. The other is actionable.
The part worth dwelling on is that this context is private and it compounds in your favour. The public model improves for everyone at once, your competitor included. Your context only ever gets richer for you, with every meeting logged, every test recorded and every review ingested. It is the part of the system a competitor cannot copy and a self-serve tool cannot ship in a box, because it is assembled entirely from work that only your business has done.
Why the combination is the moat
Each pillar earns its place alone. Together they are defensible.
The connectors are commoditised and getting more so. The base model is the same one your competitor can call with the same API key format. Neither is an advantage, because neither is yours. The advantage is the layer in the middle: numbers reconciled to definitions you chose, joined to context only you possess. That pairing is not for sale anywhere. It is the by-product of running your business with a little discipline about where things get written down.
This also reframes what the AI is actually for. It does not replace the work of defining your metrics and recording your decisions. It raises the return on that work, sharply. A brand that has built the modelled layer and fed in its context can put an analyst on top of it and trust what comes back. A brand that has not, cannot, no matter how good the underlying model gets. The model is not the moat. The architecture is.
What it does once it sits on the full picture
Once an AI is reading from the whole layer, answering questions is the floor, not the ceiling. Four things become routine, and they matter equally.
It answers anything, with a number you can trust. The follow-up that used to be a two-day ticket for whoever owns the data becomes the next sentence in a conversation. "Yes, but is that drop in returning customers concentrated in one acquisition channel" gets answered in plain language, in real time, and the figure matches your monthly review because both read from the same definition. A fixed dashboard can only answer the questions you anticipated when you built it. This answers the ones you did not, which is where the real insight usually hides.
It catches problems and brings the context with them. Running on a schedule, it watches your metrics and flags an anomaly before anyone thinks to ask, with the why already attached. Not "returning revenue dropped 12%" in isolation, but the same number sitting next to the experiment that ended last week, the flow you paused, and the review themes that have shifted. This is both pillars working at once: the number from one, the explanation from the other.
It recommends the next move, grounded in your history. Because it can see the strategy, the ICPs and every test you have run, its suggestions are not generic. It proposes the experiment that fits where you are trying to get to, tells you when you have tried something similar before and how it went, and drafts the work for you to review: the Notion experiment write-up, the campaign brief, the test config. This is the part that feels like having a growth manager sitting beside you, one who has read everything and forgets nothing.
It builds a view on the spot, and you decide if it lives. Most answers are disposable. Some deserve a chart you can filter for a few minutes. A few deserve to be kept, named and shared with the team. The old model forced you to decide which of these a piece of analysis was before it existed, which is exactly why dashboards proliferated and then rotted. Here the AI generates a one-off visualisation in seconds, and you promote it to a durable team page only if it earns the place. Permanence is decided after the answer exists, not before.
One guardrail makes all of this safe to switch on: draft, review, execute. Anything that writes to an external system produces a draft first and waits for explicit approval. The AI provides the analysis and the recommendation. You keep the final call. Nothing fires silently, which is precisely the property you want before an agent goes anywhere near your live store or your customer list.

A worked example: "why did returning revenue drop last month?"
Picture the same question on both paths.
On the raw-connector path, the AI pulls Shopify's returning-customer revenue, confirms it fell 12%, and offers the standard list: probably seasonality, maybe a softer email month, perhaps you discounted less than usual. All plausible. None of it grounded in anything that actually happened inside your business. You read it, nod, and are no closer to a decision than before you asked.
On the curated path, the AI pulls the same number from the modelled layer, then reaches into your context. It finds the winback flow you paused on the 3rd in the meeting notes. It sees the experiment that wrapped up the week before. It checks recent reviews and surfaces two mentioning a delivery delay. It comes back with something you can act on: returning revenue fell 12%, the timing lines up almost exactly with the paused winback flow, here is the test that ended just before it, and here are the two review themes worth watching, with a recommendation to reinstate the flow and a drafted experiment to confirm the effect. Then it offers you a chart of returning revenue by week, which you keep if it is worth keeping and let disappear if it is not.
Same question, same model, different substrate. One answer sounds informed. The other moves you to a decision, because it is built on what your business actually did.
What success looks like
When this is working, four things change.
Questions stop being tickets. The follow-up that used to wait two days for someone with SQL access gets answered in the same conversation it was asked in. The cost of curiosity drops to near zero, and people get more curious because of it.
The number becomes the number. Because every answer reads from the same modelled definitions, the figure you get in a casual question matches the figure in the weekly report matches the figure in the board deck. The endless "whose number is right" conversation goes away.
The advice gets specific to you. Recommendations stop sounding like a marketing blog and start referencing your own tests, your strategy and your customers. The AI reasons from your context rather than from generic best practice, which is the difference between advice you skim and advice you use.
The work starts compounding. Every metric you define and every decision you record widens what the system can do and makes the next answer better. The investment stops being a cost centre that produces dashboards nobody opens and becomes the foundation a useful analyst stands on.
This is the work we do at Crux: building the modelled insight layer for DTC brands, feeding in the context that makes it yours, and putting a growth analyst on top of it that you can actually act on. If you want to talk through what your data layer and your context layer would need to look like, email matt@gocrux.io.
Analytics and Reporting

